使用Ollama来进行本地AI模型部署教程
引言
尽管如今 AI 技术的应用已经变得无处不在,但在某些场景下,依赖在线服务可能并不理想。例如,当项目需要使用 API 接口、涉及隐私敏感数据、或者在线服务响应速度较慢时,本地部署 AI 模型便成为了一个更优的选择。
本地 AI 部署,简而言之,就是将人工智能模型、算法及其运行环境全部配置在本地设备(如个人计算机或服务器)上,从而摆脱对云端服务的依赖。这种方式的优势在于:
- 隐私与安全 :数据无需上传至云端,降低了泄露风险。
- 实时响应 :无需依赖网络,响应速度更快。
- 灵活性 :可以根据需求自由调整模型和配置。
然而,本地部署也有其局限性,尤其是对硬件的要求较高。想要运行更复杂的模型(如参数规模超过 7B 的模型),通常需要更高性能的硬件支持。对于学生群体而言,个人电脑的性能往往难以满足这些需求,因此本地部署更适合小型项目。若追求与官方 API 相当的响应质量,使用官方服务仍然是更稳妥的选择。
目前市面上有多种 AI 本地部署工具,如 LM Studio、Ollama、VLLM 等。其中,笔者认为Ollama 是当下最热门且门槛最低的工具。以下是使用Ollama 部署本地AI模型教程:
Ollama 安装(Windows)
首先访问官网下载地址下载安装包:Download Ollama on Windows
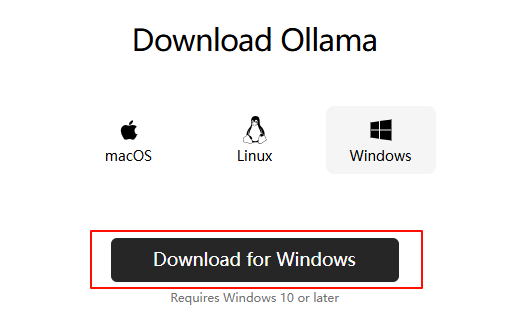
但由于官网下载源是Github速度较慢,因此可以通过Github加速或者用以下的百度网盘链接下载(分享版本为0.5.7):
链接: https://pan.baidu.com/s/18X2j3ruRxzghKMhcd7_hjA?pwd=fwrb 提取码: fwrb
然后你会得到一个700多M的OllamaSetup.exe ,双击安装程序并按照提示完成安装即可。
验证安装
打开命令提示符或 PowerShell(可右键开始图标),输入以下命令验证安装是否成功:
ollama --version
若出现版本号提示则证明安装成功

关闭开机自启(可选)
值得一提的是,Ollama安装后会开机自启,简单的关闭方式就是在任务管理器(右键任务栏)里的启动应用里找到ollama.exe并右键禁用

关闭了开机自启后要再启动可以通过运行Ollama快捷方式或者在终端中输入 ollama serve (这个得一直开着终端在后台,关闭终端就相当于退出)
安装并运行模型
打开终端(PowerShell),输入ollama run [模型名]即可下载模型并安装,初次安装后再使用该命令则直接进入聊天
示例:ollama run deepseek-r1:7b
其中deepseek-r1 是模型名,7b 是参数量,用于选择模型(不写则会按照默认下载但建议加上)
参数越大配置要求越高,要想流畅运行可以选择小模型如1.5b,但是输出质量会有所下降
Ollama 支持的模型可以访问:https://ollama.com/library
拉取的时候可能会出现下载进度倒退的问题,不用管,耐心等待直到下载完就好
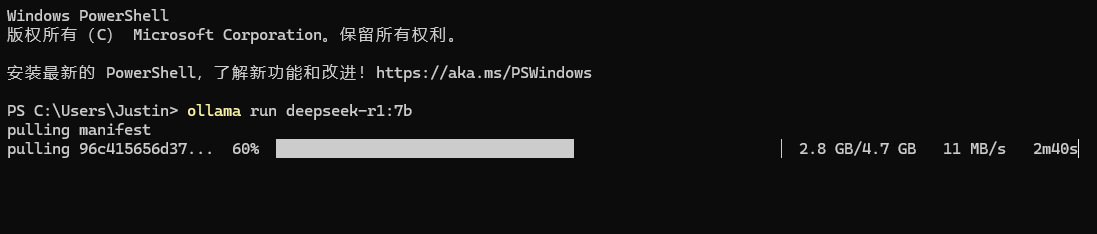
模型拉取并安装完成后就可以开始聊天了

可以看到,对于一般的对话场景,终端的使用尚可接受,但一旦涉及数学公式等内容,终端的表现就显得有些简陋了。因此,我们可以使用 Chatbox 作为更友好的聊天界面。当然,这是可选的,取决于你的使用需求(见实例)。
Chatbox 安装与使用
Chatbox 官网下载地址:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
安装后点击使用自己的API Key或本地模型或者点击右下角的设置
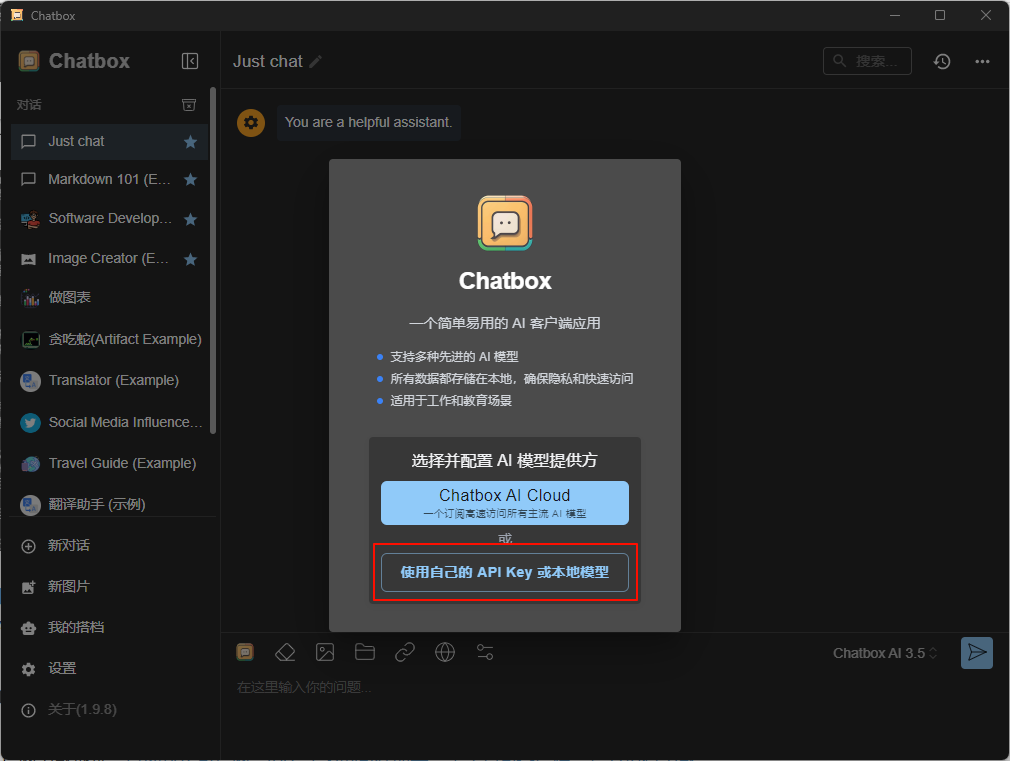
选择Ollama API ,只要Ollama是开着的,应该就能在下拉框中找到你的模型
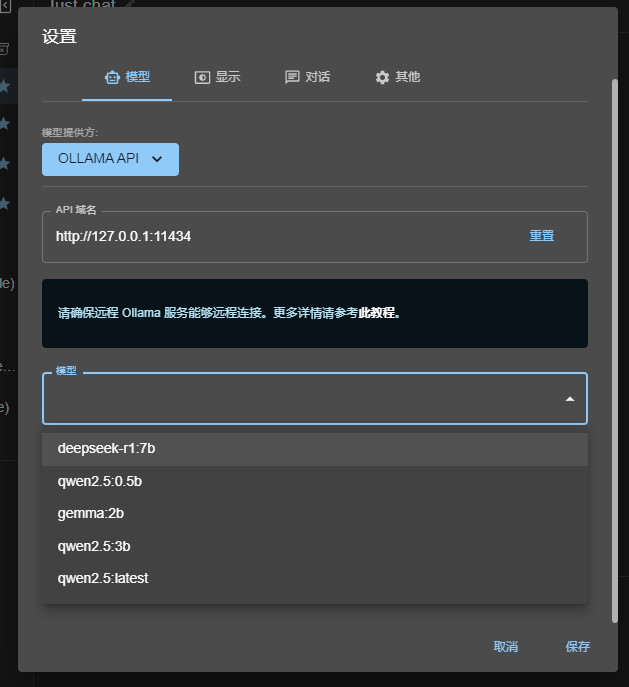
下面的两个滑动条可以根据需要更改

然后就可以聊天了,左侧不同的对话是软件预制的模版
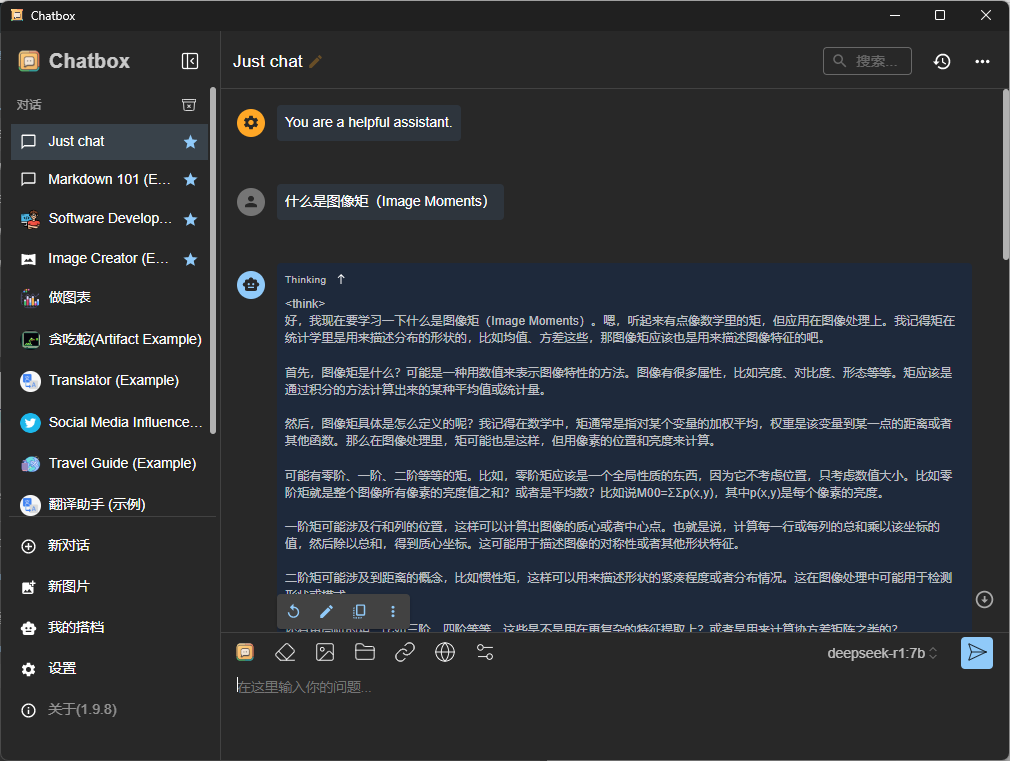
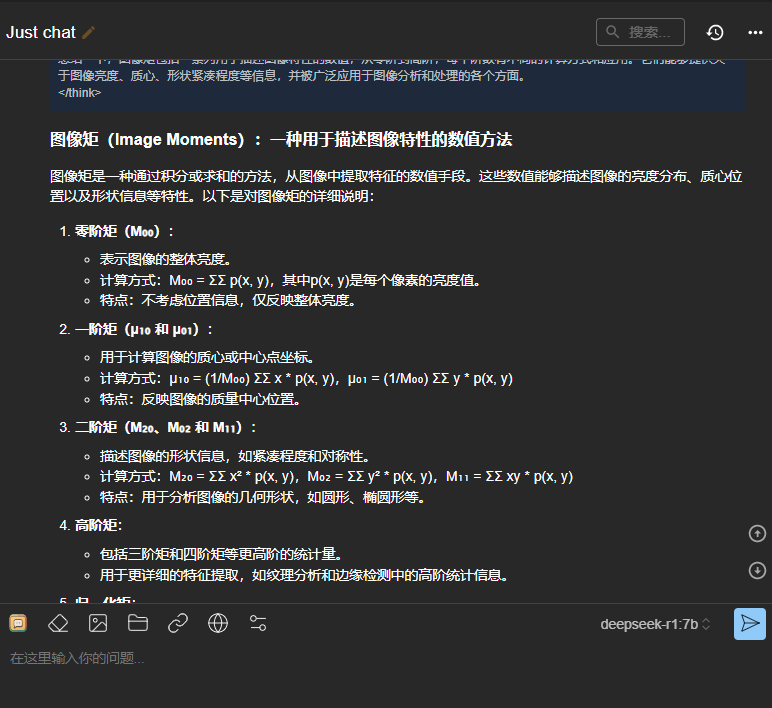
可以看到软件自动处理了Markdown文本,并且也支持Tex公式显示:

若遇到不输出问题,则可以重启一下Ollama或者使用终端输入 ollama serve 的方法(更推荐,能看见后台状态)
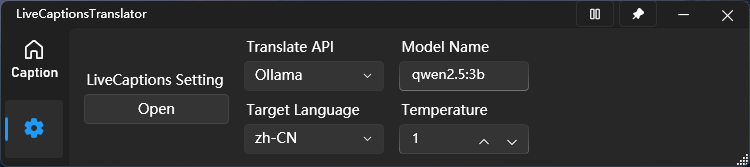
Ollama 使用实例
这是一个Github上的项目:https://github.com/SakiRinn/LiveCaptions-Translator?tab=readme-ov-file
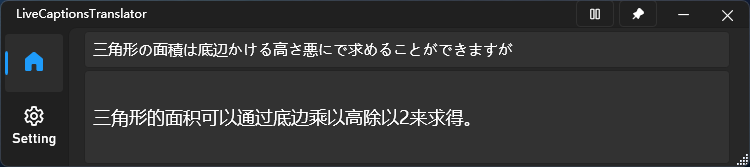
用于将翻译 API 集成到 Win11 的实时字幕中,以实现实时语音翻译。其中软件提供 Ollama API 的选项,因此,我们可以将我们的模型名输入以实现效果: